Hadoop Functionality that Needs Improvement
By Philip Russom, TDWI Research Director
[
NOTE -- My new TDWI report “Integrating Hadoop into Business Intelligence (BI) and Data Warehousing (DW)” (Hadoop4BIDW) is finished and will be published in early April. I will broadcast the report’s Webinar on April 9, 2013 at noon ET. In the meantime, I’ll leak a few of the report’s findings in this blog series. Search Twitter for #Hadoop, #TDWI, and #Hadoop4BIDW to find other leaks. Enjoy!]
Hadoop is still rather young, so it needs a number of upgrades to make it more palatable to BI professionals and mainstream organizations in general. Luckily, a number of substantial improvements are coming.
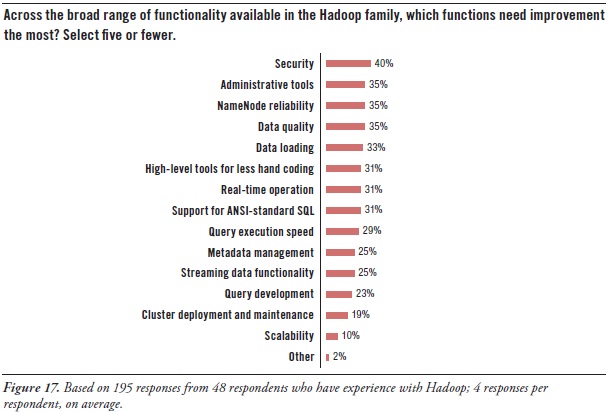
Hadoop users’ greatest needs for advancement concern security, tools, and high availability:
Security. Hadoop today includes a number of security features, such as file-permission checks and access control for job queues. But the preferred function seems to be Service Level Authorization, which is the initial authorization mechanism that ensures clients connecting to a particular Hadoop service have the necessary, pre-configured permissions. Furthermore, add-on products that provide encryption or other security measures are available for Hadoop from a few third-party vendors. Even so, there’s a need for more granular security at the table level in HBase, Hive, and HCatalog.
Administration. As noted earlier, much of Hadoop’s current evolution is at the tool level, not so much in the HDFS platform. After security, users’ most pressing need is for better administrative tools (35% in Figure 17 above), especially for cluster deployment and maintenance (19%). The good news is that a few vendors offer tools for Hadoop administration, and a major upgrade of open-source Ambari is coming soon.
High availability. HDFS has a good reputation for reliability, due to the redundancy and failover mechanisms of the cluster it sits atop. However, HDFS is currently not a high availability (HA) system, because its architecture centers around NameNode. It’s the directory tree of all files in the file system, and it tracks where file data is kept across the cluster. The problem is that NameNode is a single point of failure. While the loss of any other node (intermittently or permanently) does not result in data loss, the loss of NameNode brings the cluster down. The permanent loss of NameNode data would render the cluster's HDFS inoperable, even after restarting NameNode.
A BackupNameNode is planned to provide HA for NameNode, but Apache needs more and better contributions from the open source community before it’s operational. There’s also Hadoop SecondaryNameNode (which provides a partial, latent backup of NameNode) and third-party patches, but these fall short of true HA. In the meantime, Hadoop users protect themselves by putting NameNode on especially robust hardware and by regularly backing up NameNode’s directory tree and other metadata.
Latency issues. A number of respondents are hoping for improvements that overcome the data latency of batch-oriented Hadoop. They want Hadoop to support real-time operation (31%), fast query execution (29%), and streaming data (25%). These will be addressed soon by improvements to Hadoop products like MapReduce, Hive, and HBase, plus the new Impala query engine.
Development tools. Again, many users needs better tools for Hadoop, including development tools for metadata management (25%), query design (23%), and ANSI-standard SQL (31%), plus a higher-level approach that results in less hand coding (31%).
Want to learn more about big data and its management? Take courses at the TDWI World Conference in Chicago, May 5-10, 2013.
Enroll online.
Posted by Philip Russom, Ph.D. on April 5, 2013